Before I share some basics of a scraping effort, if you need lots of data like this, I highly recommend just reaching out to the data providers and asking for it. This can save you a lot of time and they may prefer it to you stressing their servers with multiple back-to-back automated queries.
There are lots of posts on StackOverflow on how to scrape websites, so at the risk of repeating techniques, I thought a walkthrough might be useful.
Here’s what you should know to start scraping with Python. Two essential packages are Requests and BeautifulSoup. Requests makes interacting with websites really easy and BeautifulSoup helps you parse the code behind the pages in a logical way.
Suppose you needed to know the ISO-3166 trigraphs (three-letter codes) for all of the countries in the world. Wikipedia has such a list, so you can use that page to scrape the trigraphs.
Access the page with Requests easily like this:
import requests import BeautifulSoup import pandas as pd ## the link to the site wiki_cc = 'https://en.wikipedia.org/wiki/ISO_3166-1' ## GET request to the site req = requests.get(wiki_cc)
Next, you can start parsing the page you requested using BeautifulSoup:
## grab the text from the requested page ## parse it with the HTML parser soup = BeautifulSoup(req.text, 'html.parser')
Find the table in the webpage by looking at the source code for the page (use your browser’s developer’s tools). CNTRL + F is your friend! In this case, I used CNTRL + F to look for the name of a country so that I can know where the table is:

The table starts and ends with the <tr> tag, so you can use the BeautifulSoup method findAll to retrieve all of them:
table = soup.findAll('tr')
You can now iterate through the entire table object using a loop or running the find method again. In this case, we only want the list of countries and digraphs and we can just assign them using the indices for them from the list of <tr> tags:
# this is Afghanistan to Zimbabwe countries = table[1:250]
You still need to get the data you want, though. You can build a nice lambda function to get after it. The name of the country is in the index 0 of each of the table entries list of <td> tags, and the trigraph for the country is in index 2. Use get_text on each of the target indices to grab the actual data:
cc_getter = lambda x: [x[0].get_text(), x[2].get_text()]
As a convenience, you can create a short list of field names for the data you’re going to grab. You can use it to build a dictionary:
cc_fields = ['country', 'cc']
Next, just iterate through the entries in the table, using find_all on the entry to get at each of the <td> tags you need to find. Then use the lambda function to grab the text field you want. Lastly, you can zip up data and create a list of dictionaries to create a Pandas DataFrame:
cc_dicts = [dict(zip(cc_fields, cc_getter(entry.find_all('td')))) for entry in countries]
countries_df = pd.DataFrame(cc_dicts)
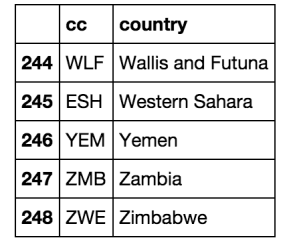
The final product (last 5 rows) will look like this:
Don’t forget you can use other ways to find things in web pages. For example, using id, div, class, type, and span can be very useful in scraping:
soup.find('span', id='target_text')
soup.find('div', class_='target_text')
soup.find('input', type='hidden')[0]['value']
Click here for the iPython Notebook for all of this code.
Hope this helps!
